Shell sort is a generalization of the Insertion Sort, it sorts subsequences that become increasingly higher, until it is reached the value n – the total number of elements.
Each subsequence i is determined by a number h_i called increment. Also, the increments must satisfy the following condition:
h_t > h_t-1 > h_t-2 > … > h_2 > h_1
Step by step example :
Having the following list, let’s try to use shell sort to arrange the numbers from lowest to greatest:
Unsorted list: 16, 4, 3, 13, 5, 6, 8, 9, 10, 11, 12, 17, 15, 18, 19, 7, 1, 2, 14, 20
This list can be divided into 3 smaller lists:
| 16 | 4 | 3 | 13 | 5 | 6 | 8 |
| 9 | 10 | 11 | 12 | 17 | 15 | 18 |
| 19 | 7 | 1 | 2 | 14 | 20 |
Now we sort each column:
First we sort the first column ( 16 9 and 19 ) to give 9 16 19
Next the second column ( 4 10 and 7 ) to give 4 7 10
Column three ( 3 11 and 1 ) to give 1 3 11
Column four ( 13 12 and 2 ) to give 2 12 13
Column five ( 5 17 and 14 ) to give 5 14 17
Column six ( 6 15 and 20 ) to give 6 15 20
and column seven ( 8 and 18 ) to give 8 18
Reassembling the array we now have:
9 4 1 2 5 6 8 16 7 3 12 14 15 18 19 10 11 13 17 20
Now, this list can be divided into 5 smaller lists:
| 9 | 4 | 1 | 2 |
| 5 | 6 | 8 | 16 |
| 7 | 3 | 12 | 14 |
| 15 | 18 | 19 | 10 |
| 11 | 13 | 17 | 20 |
We sort again each column:
| 5 | 3 | 1 | 2 |
| 7 | 4 | 8 | 10 |
| 9 | 6 | 12 | 14 |
| 11 | 13 | 17 | 16 |
| 15 | 18 | 19 | 20 |
And reassembling the list, it now looks like this:
5, 3, 1, 2, 7, 4, 8, 10, 9, 6, 12, 14, 11, 13, 17, 16, 15, 18, 19, 20
Now, this list can be divided into 10 smaller lists:
| 5 | 3 |
| 1 | 2 |
| 7 | 4 |
| 8 | 10 |
| 9 | 6 |
| 12 | 14 |
| 11 | 13 |
| 17 | 16 |
| 15 | 18 |
| 19 | 20 |
Sorting the columns again :
| 1 | 2 |
| 5 | 3 |
| 7 | 4 |
| 8 | 6 |
| 9 | 10 |
| 12 | 14 |
| 11 | 13 |
| 17 | 16 |
| 15 | 18 |
| 19 | 20 |
Reassembling we get:
1, 2, 5, 3, 7, 4, 8, 6, 9, 10, 11, 13, 12, 14, 15, 16, 17, 18, 19, 20
Most of the elements are in the right place, and the last run of the algorithm is a conventional insertion sort (this is way shell sort is considered a generalization of the insertion sort).
The generation of the increments:
The increments can be generated according to a formula, or random but it’s not recommended. Hibbard suggested a sequence 1, 3, 7, … 2 ^k – 1. The sequence 1, 4, 13, 40, 121, 364, 1093, 3280, 9841 … was recommended by Knuth in 1969. It is easy to compute (start with 1, generate the next increment by multiplying by 3 and adding 1) and leads to a relatively efficient sort, even for moderately large files.
Sample code:
#include < iostream >using namespace std;
int main()
{int a[100];
int n;
int h, x, i;
int H[100];
int t;
H[0]=1;
cout << "Please insert the number of elements to be sorted: ";
cin >> n; // The total number of elements
for(int i=1;i< =n/2;i++)
{H[i]=H[0]++; //Generate the increments
}t=n/2;
for(int i=0;i < n;i++)
{cout << "Input " << i << " element: ";
cin >> a[i]; // Adding the elements to the array
}cout << "Unsorted list:" << endl; // Displaying the unsorted array
for(int i=0;i < n;i++)
{cout << a[i] << " ";
}for(int s=t-1;s>=0;s--)
{h=H[s]; //the first increment
for(int j=h;j < = n-1;j++)
{x=a[j];
i=j-h;
while (i>=0 && x < a[i])
{a[i+h]=a[i];
i=i-h;
a[i+h]=x;
}}}cout << "Sorted list:" << endl; // Displaying the sorted array
for(int i=0;i < n;i++)
{cout << a[i] << " ";
}return 0;
}
Output:
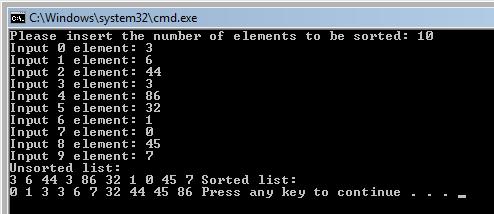
Code explanation:
for(int s=t-1;s>=0;s--)
{h=H[s];
for(int j=h;j < = n-1;j++)
{x=a[j];
i=j-h;
while (i>=0 && x < a[i])
{a[i+h]=a[i];
i=i-h;
a[i+h]=x;
}}}
The variable t is equal to the number of the elements divided by 2, so the for loop starts at the highest value then it decrements by 1 until it reaches 0. The variable h takes the first increment, in the value of H[s]. At the next for loop, using the increment value, the list is parsed to check if the elements are in the right order, and while this is false, the elements are swapped.
After the first run has been completed, the increment is changed, and again the list is parsed to check the order of the elements, just like in the example from above.
Complexity:
Defining the complexity of shell sort is hard task due to the fact that besides the implementation of the algorithm, choosing the best increment is also an issue. It could be said that on the best case, the complexity could be O(n) and on worse case O(n2). Also, depending on the gap sequence, for the worst case scenario, the best complexity is O(nlog2n).
Advantages:
- only efficient for medium size lists;
- 5 times faster than the bubble sort and a little over twice as fast as the insertion sort, its closest competitor.
Disadvantages:
- it is a complex algorithm and its not nearly as efficient as the merge, heap, and quick sorts.
- is significantly slower than the merge, heap, and quick sorts;
Conclusion:
Shell sort is faster than bubble sort or insert sort, but it’s efficient only on medium size lists. It is a complex algorithm, and defining the increments play a big role in the speed of the algorithm. Knuth defined a good formula, but Robert Sedgewick came with a sequence that he claims to be 20-30% faster than the one that Knuth recommended.
