Service Autonomy
As Businesses continue to step up the process of constructing enterprise automation logic in the service format, there is also an increasing need to step up both the efficiency and reliability that the services are intended to take on at run time. This dire need is increased when it comes time to assemble a service inventory with a vast quantity of reusable services.
Reusable Services and Concurrency
Service Oriented Architecture entails reuse to the extent that many strategic goals that are associated with enterprise wide Service Oriented Architecture transitions are linked directly to the success of achieving repeated reuse of automation logic. One of the results is that it is necessary to ensure that the services delivered do not merely possess reusable logic, but are also capable of being reused once they have been subjected to the real world.
Generally, we receive encouragement to both foster and maximize opportunities for reuse. Every service that has been classified as “reusable” tends to be made available to tons of consumer programs. The results tend to be rather predictable. As time goes on, the same service will have to facilitate the automation of several different Business tasks or processes, and may become part of several different service compositions.
Such an eventuality then translates in to an increase in usage volumes, as well as unpredictable usage scenarios. Moreover, a run time condition known as concurrent access often occurs as a result of the situation. When several service consumers simultaneously access a service, then instances of that service become spawned. How this takes place is largely determined by the vendor run time platform that is responsible for the service’s hosting.
There are, however, vital steps that must be taken in order to effectively shape the design of the service as a means of structuring the underlying service logic to best facilitate the concurrent access’s condition, not to mention other concerns related to reliability.
In this article, we will discuss the two service design principles that are extremely vital. The first is autonomous services; the second is stateless services.
If one is to construct a program that is designed for the consumption of a specific service, you may or may not be aware about the others that are already utilizing the service in question – not to mention how many users will be utilizing it in the future.
One will, in such an instance, have an expectation as to what the service is capable of doing, based on what has been expressed in the service contract as well as in a supplementary SLA. Thus, in this situation we are relying on the ability of the service to provide a level of performance, reliability and behavior that is somewhat predictable, regardless of how it is being used.
These principles’ application ultimately aids in the support of a stable and predictable inventory of services.
Service Autonomy
When it comes to the subject of decomposition, service orientation takes a very serious attitude. When constructing an enterprise service inventory, there is typically a very serious emphasis on making such every member of the inventory has been placed as a standalone building block.
In order for services to be able to provide predictable, reliable performance, then it is vital for them to exercise a massive degree of control over their underlying resources. Autonomy thus is representative of such a measure, and the principle emphasizes the need for individual services to have very high levels of individualized autonomy.
Through increasing the degree of control that a service possesses over its own environment of execution, we effectively manage to reduce the dependencies that it might otherwise need on shared resources that exist within the enterprise.
Despite the fact that we are not always able to provide a service with the exclusive ownership of the logic it encapsulates, our main goal here is for it to attain a reasonable degree of control over whatever logic it is representative of at the moment of its execution.
Owing to the fact that a variety of different measures of autonomy are capable of existing, it is helpful to make distinctions among them. In what follows, we will focus on two common levels. The first is service level autonomy.
In service level autonomy, service boundaries can be distinguished from one another even though the service might still be sharing some underlying resources. For instance, a wrapper service that encapsulates a legacy atmosphere that is also utilized independently from the service possesses autonomy in the service level. It governs the legacy system while also sharing resources with other legacy based clients.
Then there is pure autonomy. In this field, the underlying logic is under complete ownership and care of the service. This tends to be the case in those events where the logic has been built from the ground up in support of the service.
Obviously, it is a lot more beneficial for a service inventory to have purely autonomous services. It not only comes to our aid in dealing with concerns related to scalability, including concurrent access conditions, it simultaneously empowers us to position services in a more reliable fashion as a means of countering the single point of failure risk that often must be contended with when it comes to the leveraging of reusable automation logic. At the same time, because it generally requires that new service logic be rendered and often puts a demand on deployment, it can simultaneously require major expenses and efforts.
{mospagebreak title=Service Statelessness}
Service Statelessness
While autonomy may indeed be a well understood component of Information Technology, there is quite often less clarity when it comes to the constitution of state information. For this reason, we should take time out to define state management before going on to explore this particular principle.
The word “state” refers to something’s particular condition. A car moves in a state of motion; when the car is not moving, it can be said to be in a stationary state.
When it comes to Business automation, a software program has two states that tend to be associated with it. These are the active state and the passive state.
The active state symbolizes the software program that is being executed or invoked and thus enters in to a state of activity. The second state refers to when the program is not being used and thus is passive.
When programs are being designed, it is interesting for us to see what will happen when the program becomes active. It is so interesting, in fact, that designers have additional states that are applied to the program that are representative of particular types of active conditions.
In regards to the discussion of state management, two primary conditions can be evoked: they are stateless and stateful. Such terms are utilized as a means of identifying the runtime or active condition that a program is in as it can be related to the processing that is necessary for a particular task to be carried out.
When a particular task is being automated, the program may be required to process data that is specific to that particular task. This data may be referred to as “state information.”
A program might be active, but not necessarily engaged in the processing of state information. In such an idle situation, the program is thus considered as stateless. A program, on the other hand, that is actively engaged in the process of retaining or processing state information is considered to be stateful.
As processing demands on reusable services increase on a normal basis, so does the necessity for optimizing service processing logic. When engaged in the design of Service Oriented Architectures, extra attention should be paid to state management. Thus, the focus on streamlining state information management with architecture becomes emphasized to the extent that one should now have a principle that is dedicated exclusively to this aspect of service design.
That principle exists. It states that services should minimize the amount of state information that they manage, not to mention the duration for which they are stateful. In a service oriented solution, state information is typically representative of data that is particular to a service activity that is currently going on.
A service is temporarily stateful, for instance, when it is engaged in processing a message, as we can see in the diagram below. If a service is in charge of retaining state for a longer duration, then its capability of remaining available to other concurrent consumers will indeed become impeded.
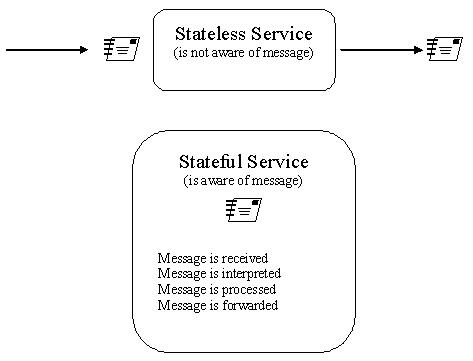
Just as in autonomy, statelessness can be the preferred condition for services. It promotes both scalability and reusability. In order for a service to retain as little state as possible, then its underlying service logic has to be designed with stateless processing considerations in mind.
Moreover, the architecture must be equipped with state deferral extensions that are supportive of the application of this principle across a vast array of different services. This is why service autonomy is a key component in any Service Oriented Architecture.
[catlist id=146].